DataView 插件介绍
定义
[[Obsidian]]插件之一,能够将Obsidian内的文档视为数据表进行检索和数据处理。
数据可识别格式
YAML格式
在Markdown文件中嵌入YAML格式的字段,能够被识别为数据
1
2
3
4
5
6
7
| #markdown content
---
#yaml content
name1: dataContent1
name2: dataContent2
|
Markdown格式
在Markdown文件中使用Name::Value的方式标记数据
1
2
3
4
5
| #markdown content
name1::dataContent1
name2::dataContent2
|
插件追加信息
dataview插件本身也会为Markdown文件加入诸多标记属性,这里使用一个打印命令将本文件的属性全部输出
1
2
| dv.paragraph(dv.current())
|
检索语法
块检索语法
使用语法标记为dataview的代码块进行检索,在其中输入检索语句进行查询
检索语法可参考SQL语法
1
2
3
4
5
| SELECT <columns>
FROM <source>
WHERE <condition>
SORT <column> [desc|asc]
GROUP BY <column>
|
SELECT 对应的关键词
- TABLE 以表格的形式展示数据,语法后接字段,表示定义
1
2
| TABLE column1, column2, column3
FROM <source>
|
- TASK 以任务形式展示数据,与LIST类似但是能够将抽出的数据作为任务生成
FROM 语法
FROM 可以从 #tag 标签获取、 从 folder 文件夹获取、从 [[link]] 链接获取,或者从链接了 link 的文件获取 outgoing([[link]])
行内代码语法
Dataview 目前支持的行内代码块主要是对于日期以及本页信息的显示,例如:
显示时间差
你可以用行内代码块计算出任意的时间差,如下:
1
| `=(date(2021-12-31)-date(today))`
|
你就可以获得相关的时间差值,如下:
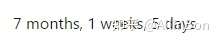
查看当前文件的信息
例如标签:
进入渲染模式后就会自动在对应的位置上显示你的当前文件的所有标签了。
DataviewJS 代码块
正如它后边附带的 JS 所言,DataviewJS 在扩展了本身的函数能力的基础上,获得了所有 API 相关的操作权限以及几乎完全的 Javascript 能力。接下来先介绍 DataviewJS 已经封装好的几个主要显示函数(目前仅能通过这些函数来显示对应的参数)。
注意,DataviewJS 代码块用 dataviewjs 而不是 dataview
DataviewJS语法也可在inline中使用,使用prefix $=即可触发,缺陷为目前无法在live preview模式下触发,需要切换到reading模式
检索
根据标签或者文件夹返回页面参数,代码参考如下:
1
2
3
4
5
6
| ```dataviewjs
dv.pages("#books") //返回所有带有标签 books 的页面
dv.pages('"folder"') //返回所有在 folder 文件夹的页面
dv.pages("#yes or -#no") //返回所有带有标签 yes 或者没有标签 no 的页面
dv.pages("") //返回所有页面
```
|
和上边类似,但是这个会返回文件路径作为参数
1
2
3
4
5
| ```dataviewjs
dv.pagePaths("#books") //返回所有带有标签 books 的页面路径
dv.pagePaths('"folder"') //返回所有在 folder 文件夹的页面路径
dv.pagePaths("#yes or -#no") //返回所有带有标签 yes 或者没有标签 no 的页面路径
```
|
用于返回单个页面作为参数
1
2
3
4
| ```dataviewjs
dv.page("Index") //返回名称为 Index 的页面
dv.page("books/The Raisin.md") //返回所有在 books 文件夹下的 The Raisin 文件的页面
```
|
渲染
用于渲染特定的文本为标题,其中 level 为层级,text 为文本。
用于渲染为段落,你可以理解成普通文本。
Dataview 封装函数
列表
1
2
3
4
5
6
7
| ```dataviewjs
dv.list([1, 2, 3]) //生成一个1,2,3的列表
dv.list(dv.pages().file.name) //生成所有文件的文件名列表
dv.list(dv.pages().file.link) //生成所有文件的文件链接列表,即双链
dv.list(dv.pages("").file.tags.distinct()) //生成所有标签的列表
dv.list(dv.pages("#book").where(p => p.rating > 7)) //生成在标签 book 内所有评分大于 7 的书本列表
```
|
任务列表
默认为 dv.taskList(tasks, groupByFile) 其中任务需要用上文获取 pages 后,再用 pages.file.tasks 来获取,例如 dv.pages("#project").file.tasks。 而当 groupByFile 为 True 或者 1 的时候,会按照文件名分组。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| ```dataviewjs
// 从所有带有标签 project 的页面中获取所有的任务生成列表
dv.taskList(dv.pages("#project").file.tasks)
// 从所有带有标签 project 的页面中获取所有的未完成任务生成列表
dv.taskList(dv.pages("#project").file.tasks
.where(t => !t.completed))
// 从所有带有标签 project 的页面中获取所有的带有特定字符的任务生成列表
// 可以设置为特定日期
dv.taskList(dv.pages("#project").file.tasks
.where(t => t.text.includes("#tag")))
// 将所有未完成且带有字符串的任务列出
dv.taskList(
dv.pages("").file.tasks
.where(t => t.text.includes("#todo") && !t.completed),1)
```
|
表格
默认为 dv.table(headers, elements) ,提供表头和元素内容即可生成对应的表格。
例如:
1
2
3
4
5
6
7
| ```dataviewjs
// 根据标签 book 对应的页面的 YAML 生成一个简单的表格,其中 map 为对应的内容所对应的表头,按顺序填入即可。
// b 可以是任意值,只是代表当前传入的文件为 b
dv.table(["File", "Genre", "Time Read", "Rating"], dv.pages("#book")
.sort(b => b.rating)
.map(b => [b.file.link, b.genre, b["time-read"], b.rating]))
```
|
看完以上的内容以后,如果你对表格或者获取的数据操作感兴趣的话,那你应该去查看官方提供的数据操作 API ,请查阅:Data Arrays | Dataview
DataviewJS 示例
以下的方案目前已经经过一部分人的使用,大呼已经满足,而如果你还有其它的需求的话,可以去请教对 Javascript 熟悉的人,或者去官方论坛请教。此处感谢提供脚本的 @tzhou 以及在官方社区的 @shabegom
标签聚合
简单版
1
2
3
4
| ```dataviewjs
// 生成所有的标签且形成列表
dv.list(dv.pages("").file.tags.distinct())
```
|
改进版
1
2
3
4
5
6
| ```dataviewjs
// 生成所有的标签且以 | 分割,修改时只需要修改 join(" | ") 里面的内容。
dv.paragraph(
dv.pages("").file.tags.distinct().map(t => {return `[${t}](${t})`}).array().join(" | ")
)
```
|

高级版
1
2
3
4
5
6
7
8
| ```dataviewjs
// 基于文件夹聚类所有的标签。
for (let group of dv.pages("").filter(p => p.file.folder != "").groupBy(p => p.file.folder.split("/")[0])) {
dv.paragraph(`## ${group.key}`);
dv.paragraph(
dv.pages(`"${group.key}"`).file.tags.distinct().map(t => {return `[${t}](${t})`}).array().sort().join(" | "));
}
```
|
效果如下:

输出内容
输出所有带有关键词的行
1
2
3
4
5
6
7
8
9
10
11
12
| ```dataviewjs
//使用时修改关键词即可
const term = "关键词"
const files = app.vault.getMarkdownFiles()
const arr = files.map(async ( file) => {
const content = await app.vault.cachedRead(file)
const lines = content.split("\n").filter(line => line.contains(term))
return lines
})
Promise.all(arr).then(values =>
dv.list(values.flat()))
```
|
如下:

输出所有带有标签的文件名以及对应行且形成表格
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
| ```dataviewjs
// 修改标签
const tag = "#active"
// 获取 Obsidian 中的所有 Markdown 文件
const files = app.vault.getMarkdownFiles()
// 将带有标签的文件筛选出来
const taggedFiles = new Set(files.reduce((acc, file) => {
const tags = app.metadataCache.getFileCache(file).tags
if (tags) {
let filtered = tags.filter(t => t.tag === tag)
if (filtered) {
return [...acc, file]
}
}
return acc
}, []))
// 创建带有标签的行数组
const arr = Array.from(taggedFiles).map(async(file) => {
const content = await app.vault.cachedRead(file)
const lines = await content.split("\n").filter(line => line.includes(tag))
return [file.name, lines]
})
// 生成表格
Promise.all(arr).then(values => {
dv.table(["file", "lines"], values)
})
```
|
输出所有带有标签的文件链接以及对应行且形成表格
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| ```dataviewjs
// 获取 Obsidian 中的所有 Markdown 文件
const files = app.vault.getMarkdownFiles()
// 将带有标签的文件以及行筛选出来
let arr = files.map(async(file) => {
const content = await app.vault.cachedRead(file)
//turn all the content into an array
let lines = await content.split("\n").filter(line => line.includes("#tag"))
return ["[["+file.name.split(".")[0]+"]]", lines]
})
// 生成表格,如果要将当前的文件排除的话,请修改其中的排除文件
Promise.all(arr).then(values => {
console.log(values)
//filter out files without "Happy" and the note with the dataview script
const exists = values.filter(value => value[1][0] && value[0] != "[[排除文件]]")
dv.table(["file", "lines"], exists)
})
```
|
如下:

输出任务
简单版
输出所有带有标签 todo 以及未完成的任务
1
2
3
4
5
6
| ```dataviewjs
// 修改其中的标签 todo
dv.taskList(
dv.pages("").file.tasks
.where(t => t.text.includes("#todo") && !t.completed),1)
```
|
改进版
输出所有带有标签 todo 以及未完成的任务,且不包含当前文件
1
2
3
4
5
6
| ```dataviewjs
// 修改其中的标签 todo 以及修改 LOLOLO
dv.taskList(
dv.pages("").where(t => { return t.file.name != "LOLOLO" }).file.tasks
.where(t => t.text.includes("#todo") && !t.completed),1)
```
|
倒计时
简单版
1
2
3
4
5
6
7
8
9
10
11
| ```dataviewjs
// 修改其中的时间,可以输出当前离倒计时的时间差。
const setTime = new Date("2021/8/15 08:00:00");
const nowTime = new Date();
const restSec = setTime.getTime() - nowTime.getTime();
const day = parseInt(restSec / (60*60*24*1000));
const str = day + "天"
dv.paragraph(str);
```
|
如下:

复杂版
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| ```dataviewjs
// 只要在任务后边加上时间(格式为 2020-01-01 ,就会在显示所有的任务的同时对应生成对应的倒计时之差
dv.paragraph(
dv.pages("").file.tasks.array().map(t => {
const reg = /\d{4}\-\d{2}\-\d{2}/;
var d = t.text.match(reg);
if (d != null) {
var date = Date.parse(d);
return `- ${t.text} -- ${Math.round((date - Date.now()) / 86400000)}天`
};
return `- ${t.text}`;
}).join("\n")
)
```
|
参考资料